


A car commercial of the future shows a driverless minivan tearing around the curves of an unfamiliar, mist-shrouded mountain road, its front seats notably empty. Children sleep trustingly inside as the minivan confidently steers itself around a sharp bend. Suddenly, a dark object drops out of the air and plummets towards the windshield. The camera pans across the vehicle’s vacant front seats and then back to the sleeping children. A booming commercial-ready voice-over asks “Is it just a plastic bag or a big rock?” On screen, the driverless minivan doesn’t hesitate. It drives confidently into the path of the unidentified airborne object that (after a dramatic pause) wafts high into the misty air before floating gently down to land at the side of the road. “It was just a plastic bag after all,” the voice intones. “When it comes to safe driving, our cars know the difference.”

Image courtesy of Bosch Mobility Solutions.
Driverless cars are developing at such a rapid rate that soon such a commercial could soon be reality. Google, Tesla, and Uber (and maybe even Apple) are successfully designing and testing robotic cars that use software and sensors to navigate traffic. Big car companies, not to be left behind, have responded to the threat to their long-entrenched incumbency by creating R&D divisions in Silicon Valley and purchasing robotics and software startups to speed up the development of their in-house driverless car technology.
In the coming decades, the automotive industry will become a new battlefield, as traditional car companies and software companies will compete (or perhaps cooperate) to sell driverless cars. Keen vision and fast physical reflexes—previously the sole domain of biological life forms—will become standard automotive features, marketed alongside a vehicle’s miles per gallon. Consumers will benefit, as intelligent driverless vehicles profoundly improve the ways in which people and physical goods move around the world. Car accidents caused by human error will no longer claims millions of lives each year. Cities will replace unsightly parking lots with parks, mixed-income housing and walkable neighborhoods. Fleets of self-driven cabs will efficiently pick people up and drop them off, and the carbon-spewing traffic jams of rush hour will become a thing of the past.
But that’s the second half of the story. Let’s take a few steps back and examine the current state of affairs. Once upon a time, cars and computers lived in separate universes. Beginning in the 1980s, software began to gradually creep into vehicles as automotive companies discovered the safety benefits of built-in automated “driver assist” technologies such as anti-lock braking systems, parking assistance, and automatic lane-keeping warnings. Today the average human-driven car boasts an impressive amount of sophisticated software. In fact, an average new car might run 100 million lines of code, that’s twice as many lines of code as were in the Windows Vista operating system (50 million lines) and nearly ten times as much code as a Boeing 787 airliner (roughly 15 million lines of code).
The fact that modern mainstream vehicles are essentially computers on wheels raises an obvious question: what’s taking so long? If cars already help us steer, brake, and park, why aren’t some of the one billion or so vehicles that roam our planet’s roads fully driverless right now? Part of the answer involves a formidable practical challenge, that of software integration. To create the computerized safety features that consumers have come to expect, automotive companies purchase driver-assist software modules from a chain of different suppliers. Since these software modules are not designed and coded from the ground up to work with one another, they exchange data at a rate that’s sufficiently fast to support the braking and steering decisions made by a human driver, but not fast enough to handle the additional processing that would be needed to provide full-blown artificial intelligence.
Speaking of artificial intelligence, another reason driverless cars are not yet a widely used mode of transportation is because of a subtle but critical distinction that roboticists make between a machine that is automated, and one that’s autonomous. While the typical new car might be highly automated, it is not yet autonomous, meaning fully self-guided. The driver-assist software systems that grace today’s cars do not have the ability to make their own driving decisions. Driverless cars are a sterling demonstration of the fact that steering a car through traffic, a seemingly simple activity that has been mastered by billions of teenagers and adults the world over, is actually an exquisitely complex demonstration of advanced robotics.
Teaching Machines to See
Since the 1950s, carmakers and roboticists have tried and failed to create cars that could liberate humans from the dangerous tedium of driving. In a research conundrum known as “Moravec’s Paradox,” roboticists have learned that it is more difficult to build software that can emulate basic human instincts than to build software that can perform advanced analytical work. Ironically, the art of creating artificial intelligence has illuminated the vast and uncharted genius of human instinct, particularly our near-miraculous mastery of perception, or what philosophers call “scene understanding.” Sometimes human perception misfires, as anyone who has eagerly pulled out a wax apple from a bowl of false fruit can attest. Most of the time, however, our lightning-quick ability to correctly classify nearby objects and react to them appropriately guides us gracefully through most situations.
Since the dawn of academic artificial intelligence research, computer scientists have attempted to build machines that demonstrate scene understanding. While efforts to create software with human-scale artificial perception have fallen short of the mark, computer scientists have succeeded admirably at creating advanced software programs that perform extraordinarily well at a highly specific task. Factory work has been automated for decades as the bolted-down mechanical arms of industrial robots, guided by highly responsive software-based controls, assess and calibrate hundreds of system variables without missing a beat. In 1997 IBM’s Deep Blue demonstrated that a computer can out-maneuver the world’s best human chess masters. Yet, building a mobile and fully autonomous robot such as a driverless car that can handle a tricky left turn during rush hour is an achievement that has eluded artificial intelligence researchers for decades.
Why can a computer play chess, but can’t tell the difference between a friendly wave from a passing pedestrian, and a stern “STOP” hand signal from a traffic cop? Because computers aren’t very good at guiding machines through unstructured environments; in other words, robots can’t think on their feet. In the case of cars, two inter-related factors considerably complicate the task of programming an autonomous vehicle: one, the challenge of building software and a visual system that can match the level of performance of human reflexes. Two, the fact that a driverless car needs software intelligent enough to handle unexpected situations, or what roboticists call “corner cases.”
For most of the 20th century, software programs have been confined to analytical work. Part of the problem has been mechanical, that computer hardware was too primitive to support the rapid calculations and vast amount of data inputs needed to simulate human perception. In addition, for most of their history, computers have been large, fragile and (by today’s standards) laboriously slow. As a result, programmers had to write software code that was “parsimonious,” meaning it ran off of very little data and could function efficiently on a meager amount of available memory and computing power. It didn’t help that until the advent of desktop computing, access to precious high-powered hardware and software was carefully doled out to a small universe of academic and industrial researchers.
The prevailing mode of artificial intelligence software that developed in the midst of these constraints was built on the notion of structured logic. If the field of artificial intelligence research were a tree, its mighty trunk would branch into two large forks, one fork being a school of thought that favors structured logic, and the other an alternative approach called “machine learning.” From the 1960s through the 1990s, the structured logic approach, called “symbolic AI,” ruled the roost in university computer science departments. The other fork of the tree, machine learning software, was relegated to the sidelines as an interesting, but not very elegant way to create artificial intelligence.
Symbolic AI is essentially a recipe that instructs the computer through a series of precise, written set of rules. Using symbolic AI, researchers tried to emulate human intelligence by anticipating and writing a rule to address every single possible situation a program (or robot) might later encounter, essentially flattening the chaotic, three-dimensional world into elaborate sets of if/then statements. Rule-based AI had such a strong grip on the field of artificial intelligence research that in 1988 in a series of interviews on public television, noted comparative mythology scholar and anthropologist, Joseph Campbell, quipped “Computers are like Old Testament gods; lots of rules and no mercy.” (Campbell, The Power of Myth).
For most of the 20th century, Campbell’s description was a fitting one. Software based on structured logic works well for automating activities that have a finite number of “moves” or take place within a confined environment, for example, playing chess or overseeing a repetitive task on an assembly line. While rule-based AI remains a powerful analytical tool that’s in widespread use today, it proved to be of limited value for automating environments brimming with corner cases, the unpredictable situations beyond the reach of pre-determined rules. Real-world environments are irrational, shaped by an infinite number of ever-shifting rules.
Despite its limitations, as recently as 2007, pioneers of self-driving car research used rule-based code to build their vehicles’ computer vision systems, resulting in software that was wooden and inflexible. To automate a driverless car that could roll with the punches on public streets and highways, some other sort of software was needed. Two inter-related forces broke the stalemate: one was Moore’s Law, the simultaneous rapid growth and drop in price of computing power. The second disruptive force was the rapid maturation of “deep learning” software.
If you recall the giant two-pronged tree of artificial intelligence, deep learning software is a sub-branch of machine learning. Unlike symbolic AI, machine learning software does not use formal logic to give artificial life to software, but instead, uses algorithms to model statistical relationships between selected phenomena. To create a machine learning application, the role of the human programmer is to define a body of data, choose the appropriate algorithm to parse that data, and then “train” the software to perform a particular task. Training involves using a process of trial and error in which the learning algorithm adjusts the weight assigned to the variables in a statistical model until that model performs at a satisfactory level. Sometimes called “bottom up” AI, a machine learning program needs large amounts of data in order to be trained and refined.
Because of its gluttonous appetite for data and inexpensive computing power, machine learning languished in the sidelines for most of the 20th century. As early as 1957, the principles that underlie modern deep learning were demonstrated by computer scientist Frank Rosenblatt, who built a machine he called “The Perceptron,” a giant contraption made of transistors and colored lights that learned to recognize simple shapes. Modern deep learning was dramatically launched in 2012 at an annual image recognition competition. A team of researchers from the University of Toronto designed a novel machine learning program that demonstrated record-breaking levels of accuracy in recognizing selected objects in pictures pulled at random from the Internet. Their network, a deep learning program called SuperVision, examined thousands of digital images and labelled them with a rate of 85% accuracy, approximately half the error rate of the competitors.

Neural network pioneer, Frank Rosenblatt, left.
Powerful deep learning networks such as SuperVision could flourish once digital images became abundant, and processing power became cheap. Deep learning belongs to a sub-sub-branch of machine learning called neural networks. A deep learning network is made up of hundreds of layers of grid-like arrays of artificial “neurons.” The process works as follows. A digital image is copied into the first layer of the deep learning neural network. Then the image is handed to the next internal layer of the network which detects small patterns, or “visual features,” marks those features, and hands the image off again to the following layer. At the end of its journey through dozens (or even hundreds) of layers that make up the network, the information in the original image has been transformed into visually unrecognizable—but statistically meaningful—patterns that correspond to the notion of a cat, a dog, a stop sign, or anything else the network has been trained to identify.
The job of the human programmer is to provide ample examples of the object the network is learning to “see” and the training algorithm takes care of the rest. The training algorithm improves the performance of the deep learning network by repeatedly reducing the weight of the individual artificial neurons that have been responsible for making wrong decisions, and increasing the weight of neurons that made correct decisions. The fact that a deep learning network can transform an image of a cat into a simple yes/no answer to the question “is this a cat?” simply by using a series of tiny steps sounds miraculous. Yet the process works surprisingly well. At the same image recognition competition where SuperVision crushed its competition, three years later, another artificial neural network won the 2015 competition by identifying objects in digital images with a level of accuracy greater than that of an average human.
Teaching a software program to recognize cats or shoes by showing it thousands and thousands of random digital images sounds of little practical value for automating the task of driving. Yet deep learning software has proven to be the long-awaited missing link in the evolution of artificial life. A deep learning network can be trained to spot objects that are commonly found by the side of the road such as bicycles, pedestrians and construction sites. This is why Google’s autonomous vehicles continue to prowl around the streets, gathering data to build a giant motherlode of driving experiences. Once a deep learning network classifies what’s near the vehicle, it hands off that insight to the car’s operating system. The operating system—a suite of different types of on-board software modules—learns to react appropriately to a wide variety of driving situations until the driverless vehicle attains human-level artificial perception and reflexes.

Artificial Senses and Reflexes
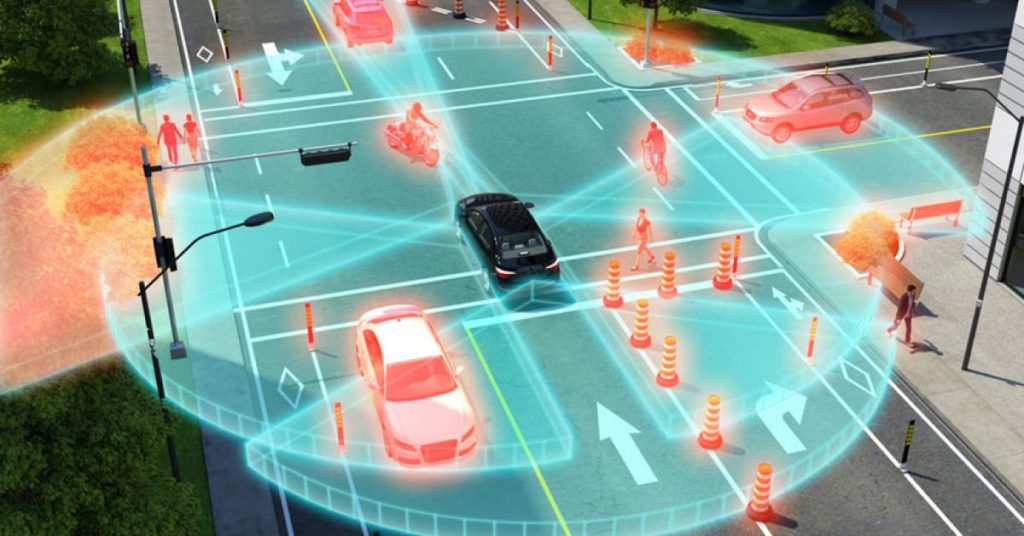
Meanwhile, while AI research was revitalized by abundant data and cheap computing power, a parallel revolution was taking place in the on-board hardware devices that serve as a vehicle’s artificial eyes, ears, hands and feet. Driverless cars track their location with a GPS device that can identify a car’s whereabouts to within a few feet. The GPS is supplemented with another device called an Inertial Measurement Unit (IMU), a multi-purpose device that contains acceleration and orientation sensors and keeps track of the car’s progress on a stored, on-board high-definition digital map. One of the IMU’s functions is to augment the GPS by keeping track of how far and fast the vehicle has travelled from its last known physical location. The IMU also serves as the equivalent of a human inner ear, so it senses if the car is tipping dangerously far in any direction and informs the car’s guiding software to correct the situation.
Radar sensors, once so giant and delicate they had to be mounted on a standing tower, are now tiny enough to be installed on the sides of the car. Radar sensors send electromagnetic waves to sense the size and velocity of physical objects near the vehicle. Another key optical sensor is perhaps the most iconic, the cone-shaped LiDAR (laser radar) devices that graced the tops of Google’s driverless Priuses. A LiDAR device creates a three-dimensional digital model of the physical environment that surrounds a driverless vehicle by “spray painting” the vicinity with spinning laser beams of light. As these beams of light land on nearby physical objects and bounce back, the LiDAR device times their journey and calculates the object’s distance.
LiDAR operation. Image courtesy of LeddarTech.
The data generated by a LiDAR is fed to on-board software that puts together the information into a digital model called a “point cloud.” A point cloud depicts the shape of the physical world outside the car in real time. One of the major drawbacks of using laser beams to build a digital point cloud is that the spinning lasers do not recognize and record color. Another shortcoming of LiDAR is that despite modern high-speed processors, generating a point cloud is a relatively time-intensive process more suited to surveying static environments (such as geological formations), but too slow for use in emergency driving situations. For these reasons, LiDAR is teamed with several digital cameras that are mounted on different parts of the driverless car.
Digital camera technology has benefitted tremendously from Moore’s Law, as cameras have shrunk in size and cost while the resolution of digital images has increased. A digital camera gathers light particles called “photons” through its lens. It stores the photons on a silicon wafer in a grid of tiny photoreceptor cells. Each photoreceptor cell absorbs its appropriate share of photons. To store the light energy, each photoreceptor translates the photons into electrons, or electrical charges: the brighter the light, the larger the number of photons and ultimately, the stronger the captured electrical charge. At this point, the visual data captured in a digital image can be transformed into a nomenclature a computer can understand: a pixel, or “picture element” represented by a number. The grids of numbers are fed directly into a deep learning network, then to the car’s on-board operating system, which integrates data from all over the vehicle, analyzes it, and chooses an appropriate response.
If visual sensors and navigational devices act as the equivalent of human senses, another innovative family of hardware devices called “actuators” serve as mechanical hands and feet. Before the digital era, actuators were mechanical contraptions that used hydraulic or mechanical controls to physically pull, push or otherwise manipulate a particular machine part. Modern actuators are electronically linked with the car’s software subsystem by an on-board local network called a “drive by wire” system. The drive by wire system uses a controller area network (CAN) bus protocol that zips data around at a rate of approximately one megabit per second so all the moving parts of the car can communicate with the software subsystems and react when necessary.
A body of knowledge called controls engineering is applied to maintain the smooth functionality of the various hardware devices and mechanical systems on a driverless vehicle. One set of controls oversees the vehicle’s route-planning and navigation controls by using algorithms to parse the data from the GPS and IMU devices, rank several possible outcomes, and select the optimal route. Another family of controls (sometimes known as “low-level controls”) use feedback loops to maintain the system’s equilibrium and pull the system back to a pre-set, steady state. Early feedback controls used in factory machinery were mechanical affairs—cables or pulleys or valves—that regulated a machine’s speed, moisture or temperature. Modern feedback controls are digital, relying on software that reacts to inflowing sensor data and responds by applying control algorithms to maintain the system’s optimal level of performance.
Moore’s Law will continue to improve the performance of sensors and on-board artificial intelligence software. A car’s artificial eyes—its on-board digital cameras and other types of visual sensors—can already see further than human eyes, even in the darkness. Individual driverless cars will share data and experiences with each other, creating a giant pool of shared collective knowledge of roads, speed limits, and dangerous situations. As they gain experience, when the correct reaction means the difference between life and death, driverless cars will save lives by quickly and calmly ranking the outcomes of several possible outcomes and choosing the most optimal one. In time, driverless cars will boast artificial perception that that’s more rapid and fluid than that of the most alert, sober, and skilled human driver.
The Road Ahead
As the hardware and software near human-level physical dexterity and perception, what barriers remain to the widespread adoption of driverless vehicles? Ironically, technological barriers will prove to be relatively straightforward compared to the potential obstacles that could be posed by people, organizations and politics. To combat the pernicious creep of special interests, intelligent regulation will be needed.
One formidable challenge will be the definition and enforcement of transparent and rigorous safety standards for driverless car software and hardware. Car and technology companies, consumers, and state and federal legislators will need to set aside their individual agendas and work together to implement a framework for safety testing similar to those used by the aviation industry. In the United States, the USDOT has taken some cautious steps to address driverless vehicles, but so far, has stayed away from specific guidance, preferring to leave that up to the individual states.
In addition to safety, individual freedom, safety and privacy will be at stake. While driverless cars will save millions of lives that would have been lost to car accidents, new dangers and costs will emerge. A driverless car, like a computer, could be hacked remotely and steered off the road, or its passengers hijacked and driven somewhere against their will. As driverless taxis are installed with facial recognition software, customer privacy could be compromised, or at best, sold out to corporations who will launch merciless and intrusive marketing campaigns. Other hardships will be economic, that millions of truck and taxis drivers all over the world will lose their jobs.
Personal mobility could become a human rights issue. Today’s battles fought over the ethics of doling out of internet bandwidth to deep-pocketed corporations will pale in comparison to the battles that will be fought over control of driverless cars software. Authoritarian governments may attempt to impose a kind of “physical censorship” on targeted individuals, limiting their travel to a short list of pre-approved destinations and preventing them from driving together with people whose name appears on government watchlists.
Another political risk is that in order to buy themselves time to improve their in-house robotic capabilities, hard-lobbying car companies will attempt to convince legislators to enforce a gradual approach to automated driving in the name of “safety.” If this happens, the Federal agency that oversees automobiles, the United States Department of Transportation (USDOT) could be convinced to delay the development and testing of full-on transportation robots in favor of increasingly partially automated vehicles. On the other hand, if car companies are able to rapidly master the art of robotic-building and can find an appealing business model in commercializing fully autonomous vehicles, the automotive industry could become a passionate advocate of driverless cars, and instead, lobby for their commercialization.
Although cars and computers have been around for nearly a century, the two have not yet fully embraced one another… until now. Driverless cars are the brilliant product of the union of automotive and computer technologies. As artificial intelligence technology finally matures, intelligent, driverless vehicles will save time, lives, and create new opportunities for cities and businesses, but only if legal and regulatory frameworks can keep up.
About the Authors
 Melba Kurman writes and speaks about disruptive technologies. Hod Lipson is a roboticist and professor of engineering at Columbia University. They are co-authors of Driverless: Intelligent Cars and the Road Ahead.
Melba Kurman writes and speaks about disruptive technologies. Hod Lipson is a roboticist and professor of engineering at Columbia University. They are co-authors of Driverless: Intelligent Cars and the Road Ahead.
Previous

